Yesterday I managed to solve a long standing issue with the help of someone from the community.
To me a nice example of what can be the hidden costs of running an open source platform with a lot of moving parts.
My takes on Openshift and OKD after a year of experience is for some other time.
The problem
An image says more than a thousand words is the cliché so here we go:
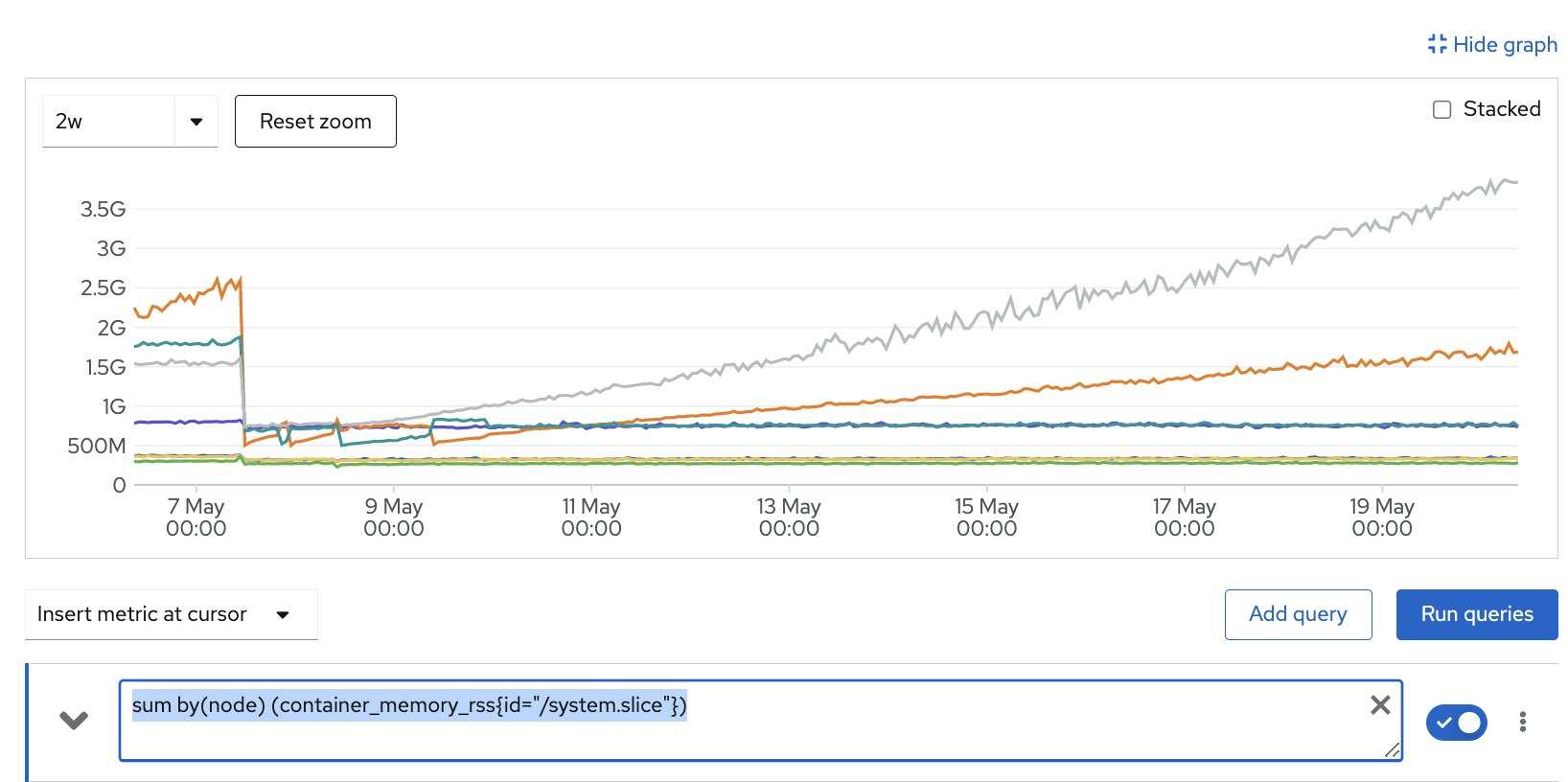
The picture shows the memory usage of the so called system.slice on our production cluster. All system processes such as systemd, the container runtime crio and some system services such as NTP clock synchronization.
There is a monitor check that, out of the box, triggers an alert when the usage exceeds 1G. The check is there to assure Kubernetes (kubelet) can correctly calculate available memory when reserving 1G for the system to avoid unexpected OOM events.
We saw the alert pop up after a few days runtime after node restarts due to some core config changes or an automated upgrade process.
Since our worker nodes have an abundance of resources and automated rolling reboots where a regular event in the young life of the cluster it was not an immediate worry.
Until recently: all production load is moved to the new OKD cluster so now stability is key. Rolling reboots will take place less often and usually only during regular maintenance windows for OKD upgrades.
As you can see, with our current moderate load the curve is going up exponentially on one node.
Still not really urgent, but regularly I would need to drain a node and restart the crio service and or reboot the node. Not really something we want in production since it can introduce a short downtime in our current setup. The reason why is for another time. At least it would mean I need to work regularly on some unforgiving hour at night or in the morning, nobody wants that.
Debugging
Basic debugging took place over many months, here the key findings.
CRIO eats memory
This was clear as soon as I found out about this systemd command:
systemd-cgtop system.slice
crio is eating the bulk of the memory
Kubelet is wasting CPU cycles on resources involving long gone PODs
Next clue is the excessive CPU usage of the kubelet process. At the peak shown in the initial graph, kubelet was keeping 10-14 cores constantly busy. Not really an immediate problem four our dual CPU nodes but still, the Kubernetes control plane should behave better. And it does, in my experience, so something must be going on.
You can easily follow the kubelet logs using:
journalctl -u kubelet -f
It is immediately obvious kubelet is wasting time on trying to find stuff about deleted pods. There is a Redhat issue describing a similar issue: https://bugzilla.redhat.com/show_bug.cgi?id=2080253
Now, it points to an upstream Kubernetes issue that would also point me to the workaround mentioned later but at the time it was not mentioned yet.
Why node 4 ?
So the graph clearly shows that one node is suffering a lot worse than the others. So I listed the pods on this node using:
oc get po -o wide -A | grep worker-04
oc is the kubectl of Openshift by the way. In this context you could just as well use kubectl.
I soon figured out that one of our services had a cron job launching short lived pods every two minutes. The Kubernetes sheduler almost always chose node 4 probably because it has the smallest load.
This is about as far as I got, so let’s summarize:
- kubelet wastes CPU (probably rising exponentially)
- CRIO memory rises exponentially
- Regular pod deletions seems to be the cause
The community
Pretty jaw dropping problem if you ask me: a container orchestration thing does not manage to delete pods without leakage causing catastrophic node failure sooner or later, depending on your resources.
So I couldn’t really believe my eyes, I probably did something wrong myself, and decided to ask the community to see if I was the only one. I resorted to the ‘#openshift-users’ Slack channel in the Kubernetes Slack.
Yesterday was the second time I asked my question and now I got my answer fairly quick. A friendly person pointed me out to the upstream Kubernetes issue: https://github.com/kubernetes/kubernetes/issues/106957
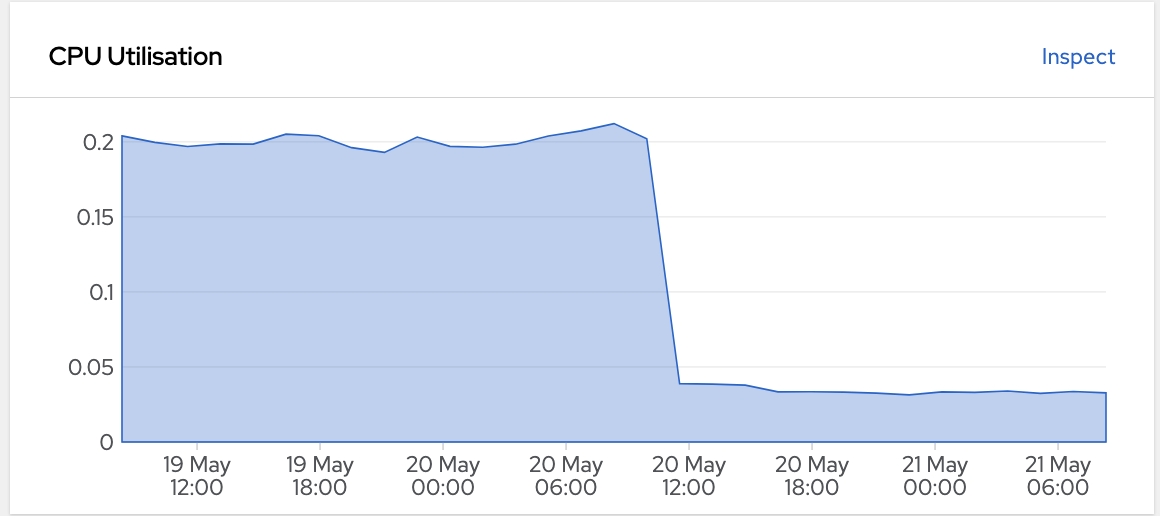
He already pasted a script there that fixes the problem by finding cgroups that are left behind and deleting them. Running that script immedialy made memory and CPU usage drop to normal levels again, so I was stoked, finally fixed!
The final solution
The friendly guy also promised me to pass the full Kubernetes definitions soon, to run this as a DaemonSet on your cluster. Every ten minutes left behind stuff is cleaned up.
Maybe it is not gonna win a beauty contest but it is very effective: https://gist.github.com/aneagoe/6e18aaff48333ec059d0c1283b06813f
Until the upstream folks and/or crio maintainers can fix this, this is the best we can do.
Check the CPU usage graph of the most infected node before and after:
Conclusion
Open source brings costs because these problems have to be debugged. It is key you follow issue trackers of all critical moving parts: crio, kubernetes, OKD, CoreOS, …
This takes time from someone in your organization or from consultants, which is usually not free. If ignored, you will suffer downtime. Again, this will cost you money and probably more.
You could of course just pay RedHat and get yourself a nice Openshift setup with their support. I have no idea to be honest, but sometimes I suspect they have an internal hidden issue tracker with blocking open source issues to upgrade Openshift to a version closer to the most recent OKD.
And why is this issue not somewhere on a web page with known issues and workarounds? At least I did not find it.
But I don’t mind of course: debugging problems and learning new ways to work more efficient than the day before is what I do. And thanks to the friendly community, I didn’t even need to debug this all the way down.
Another lesson for me is that there is some low level stuff I don’t understand yet about how the container runtime and kubelet interact. I am definitely triggered to close this gap some time soon.
Lastly, the open source community is so friendly and giving. I should do more to help, f.e. answering more questions in the Slack channel.